FCR — first-contact resolution — is the metric that predicts support team health more reliably than any other single number. Not ticket volume. Not average handle time. Not CSAT by itself. FCR, because it directly measures whether your support organization is actually solving problems or just processing contacts. And in SaaS, where churn lives in the friction of unresolved problems, FCR is a retention lever that finance teams can model against.
This is the operational playbook we walk through with every team that comes to Resolvemark. The principles apply whether you're running a fully human team, a hybrid of human and automation, or a mostly-automated queue. The math doesn't change. The levers are the same.
Step 1: Measure FCR Accurately Before You Try to Improve It
Most support teams are measuring FCR wrong. The common mistake is using ticket reopens as the proxy: if a ticket wasn't reopened, it was resolved on first contact. That methodology misses every customer who gave up instead of reopening, every customer who came back through a different channel, and every customer who called in instead of submitting a second ticket. Each of those is a failed FCR that your dashboard doesn't see.
The more accurate approach combines three signals: ticket reopen rate (baseline), same-customer contact within 72 hours (catches channel-switching), and post-interaction survey data asking explicitly "was your issue fully resolved?" (catches silent failure). Running all three gives you an FCR estimate that's 15–25 percentage points lower than reopen-only measurement — which is uncomfortable, but accurate. You can't improve a number you're not measuring correctly.
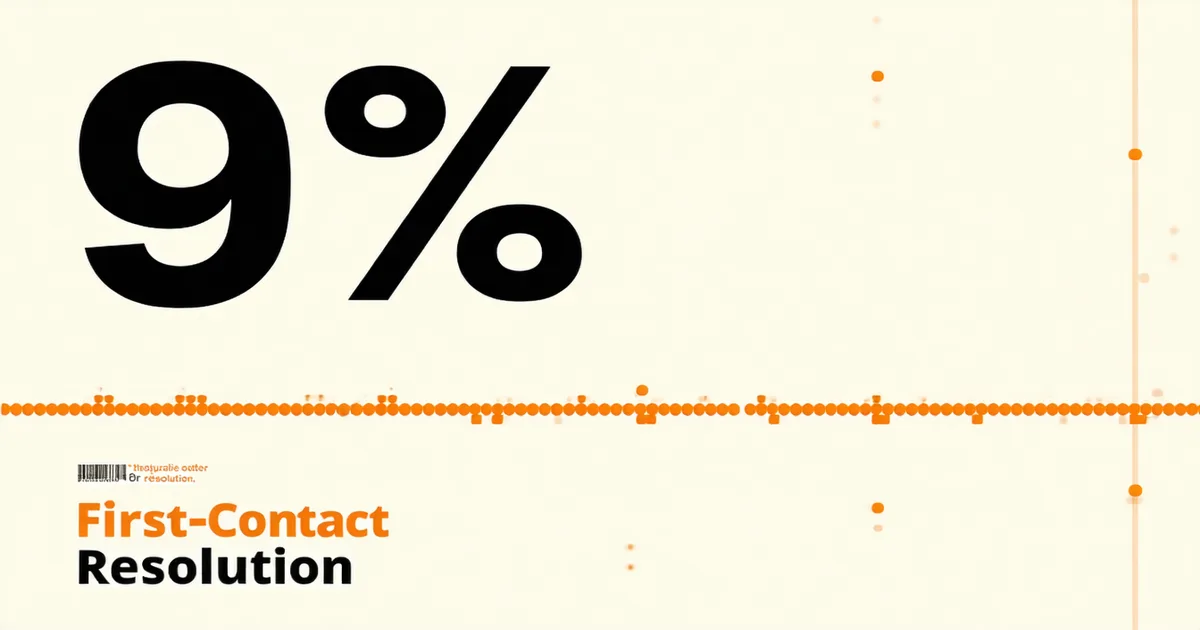
When we audit support operations before onboarding, the first thing we ask for is FCR data with methodology. Teams measuring only reopens typically discover their actual FCR is 55–65% when measured properly. Teams that know this are in a much better position than teams still operating with an inflated 80% number that doesn't account for silent failure.
Step 2: Classify Your Volume by Resolution Barrier
Once you have an honest FCR baseline, the next step is categorizing your open tickets by what's actually preventing first-contact resolution. In practice, almost every FCR failure traces to one of four root causes:
- Knowledge gap: The agent (human or automated) didn't have the information needed to resolve. KB articles are missing, outdated, or written at the wrong level of abstraction. Most common in onboarding-related tickets after a product release.
- Tooling gap: The agent had the knowledge but couldn't take the action. No write access to the billing system. No ability to issue a refund without supervisor approval. No integration to trigger the downstream event.
- Authorization gap: The action required approval that takes longer than one interaction. Refunds over a threshold, plan changes for enterprise accounts, credits that need manager sign-off. Policy structure forced a multi-step process into a single-contact problem.
- Classification failure: The ticket was categorized or routed incorrectly, so it reached an agent who couldn't resolve it in the first place. This is the sneakiest FCR killer because it looks like a random spread in the data rather than a systematic pattern.
Sample 50–100 of your unresolved or reopened tickets from the past 30 days. Code each one against these four categories. The distribution tells you exactly where to focus. If 60% of your FCR failures are authorization gaps, a knowledge base overhaul won't move the needle — you need to rewrite your approval policies. If 70% are tooling gaps, automation is the right investment, not training.
Step 3: Address Knowledge Gaps Systematically
Knowledge gaps have a well-known lifecycle in SaaS support: a product feature ships, the KB articles lag by 2–6 weeks, and during that window every question about the new feature becomes an FCR failure. Multiply that across 4–8 releases per quarter and your KB is structurally stale by design.
The fix isn't to write faster — it's to wire product releases to KB updates automatically. Before any release ships, the KB update for that feature is part of the release checklist, not a post-release to-do. The best support ops teams we've encountered require a KB article draft as part of the feature spec, reviewed by support ops before the release is marked complete.
For AI support systems specifically, KB staleness has a direct FCR cost because RAG pipelines are only as accurate as the documents they retrieve from. An AI agent answering from a KB that doesn't reflect the current product state will produce confident-sounding wrong answers — a specific category of failure that's harder to detect than "no answer found" and more damaging to CSAT because the customer acted on bad information.
Step 4: Remove Authorization Bottlenecks on High-Volume Actions
Authorization gaps are a policy problem, not a training problem. If your FCR failures cluster around "refund requires manager approval" and you're handling 200 refund requests per month, you need to calculate the total cost of that approval workflow before defending it.
Here's the arithmetic: 200 refunds/month × average $25 refund value × 2 contacts per failed-FCR (the original plus the follow-up) × 8 minutes AHT = 3,200 additional agent-minutes per month spent on authorization overhead alone. At a fully-loaded cost of $0.50/agent-minute, that's $1,600/month in authorization-delay costs — almost certainly more than the fraud risk the approval step is meant to prevent for refunds under a reasonable threshold.
We're not saying all approval gates are wrong. For enterprise contract modifications, large-value credits, or actions with irreversible account consequences, human review makes sense. The issue is applying enterprise-grade approval friction to routine consumer support operations. Review your authorization thresholds annually against actual fraud and error rates, and remove the gates that are costing more than the risk they're managing.
Step 5: Track FCR Separately for Automated and Human Resolutions
As automation enters the support queue, FCR splits into two separate measurements: FCR for automated resolutions and FCR for human-agent resolutions. These numbers behave differently and improve through different interventions.
Automated FCR improves through: better intent classification (fewer wrong-action errors), KB coverage (fewer knowledge gaps), and tighter confidence thresholds (fewer low-confidence actions taken autonomously). Human FCR improves through: agent tooling (write access, integrated views), training (especially on newly released features), and streamlined authorization policies.
Teams that blend these into a single FCR number lose the diagnostic signal. A 75% blended FCR that's actually 90% automated FCR and 55% human FCR suggests the human agents are the constraint — the automation is working. A 75% blended FCR that's actually 65% automated FCR and 88% human FCR suggests the automation is the weak link. These require completely different remediation strategies, and they're invisible when blended.
The FCR Improvement Curve
Practical FCR improvement follows a predictable curve. The first 15 percentage points of improvement come from structural fixes: measuring correctly, addressing the dominant barrier category, removing the highest-friction authorization gates. These improvements are often achievable in 60–90 days with focused effort.
The next 10–15 points require systemic change: integrating support tooling more deeply (so agents can take more actions in fewer clicks), building the KB feedback loop (so gaps surface automatically from tickets), and deploying automation for the highest-volume, most-structured request types. This phase takes 3–6 months.
Beyond 90% FCR, the remaining failures are complex, idiosyncratic edge cases — the kind of issues that genuinely require experienced human judgment and can't be systematized. At that point, FCR improvement is about staffing quality and senior agent development, not process or tooling. Most mid-market SaaS support operations don't reach this ceiling before hitting other constraints, but it's worth knowing where the real asymptote is.
The teams that move fastest on FCR are not the ones with the biggest budgets. They're the ones who measure it honestly, classify their failures accurately, and address the dominant barrier category systematically. Start there.